Нажмите куда угодно, чтобы закрыть · ESC
 ППК СГТУ
ППК СГТУ.env. Защита токенов от утечки.user_sessions.json.@telegram_bot.message_handler(content_types=["voice"])
def audio_processing(message: Any) -> None:
assistant.process_voice_message(message)
def process_voice_message(self, message: Any) -> None:
# 1. Скачать OGG-файл из Telegram
file_info = self.bot.get_file(message.voice.file_id)
voice_bytes = self.bot.download_file(file_info.file_path)
# 2. Транскрибировать через Groq Whisper-large-v3
transcription = self.voice_service.transcribe_telegram_voice(voice_bytes)
recognized_text = metadata_value(transcription, "text", "").strip()
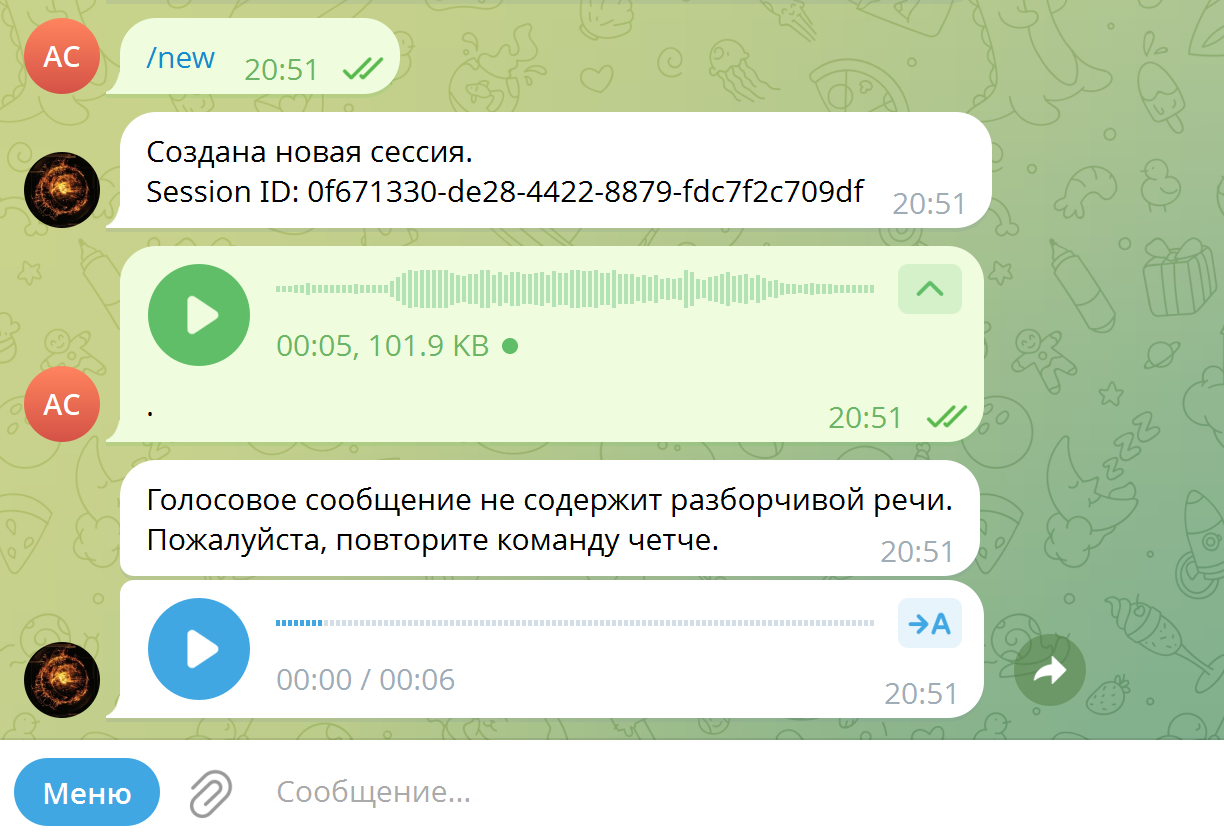
# 3. Фильтр нераспознанной речи (4 порога)
if is_unintelligible_transcription(transcription):
self.bot.send_message(message.from_user.id, UNINTELLIGIBLE_VOICE_MESSAGE)
return
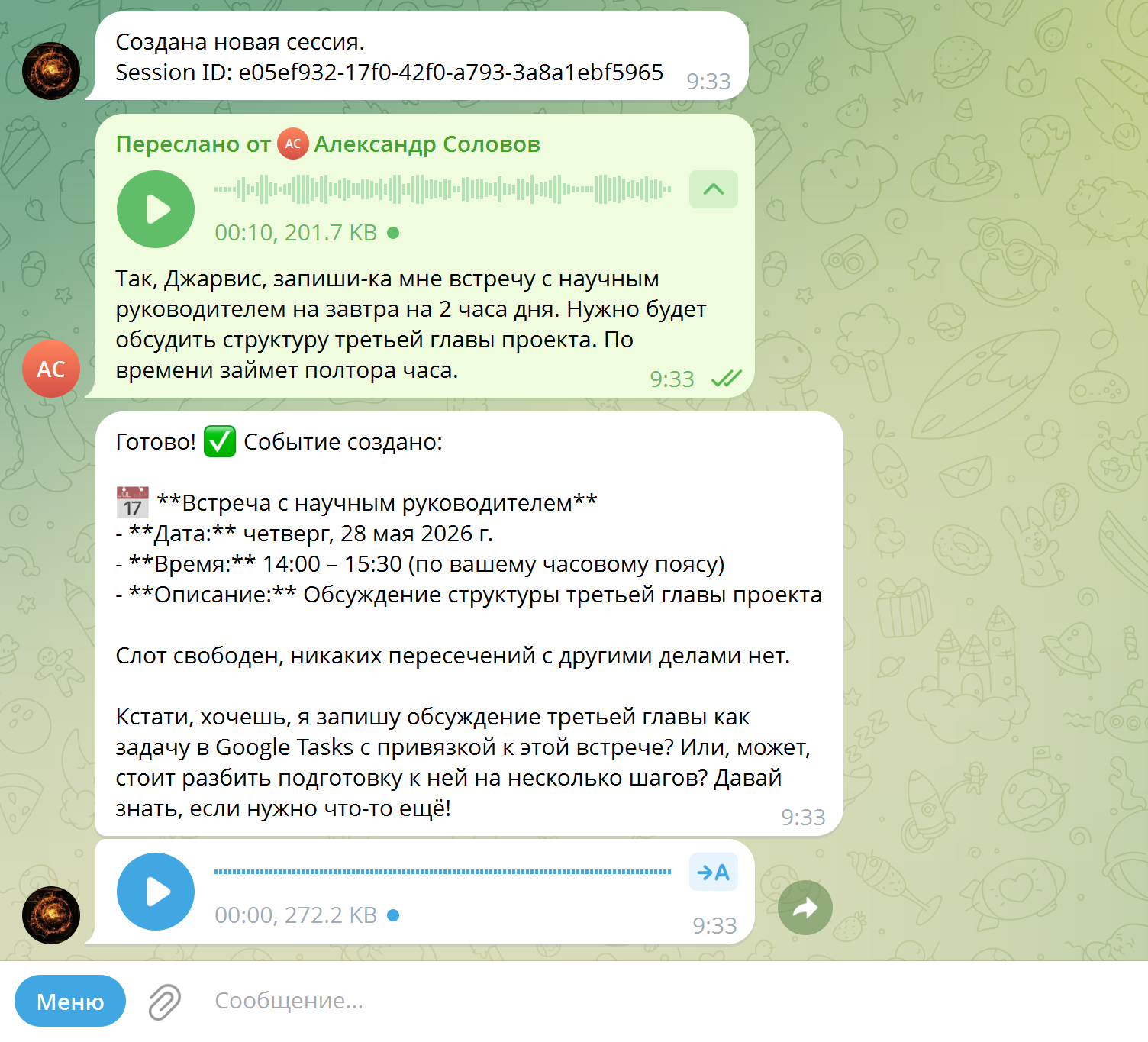
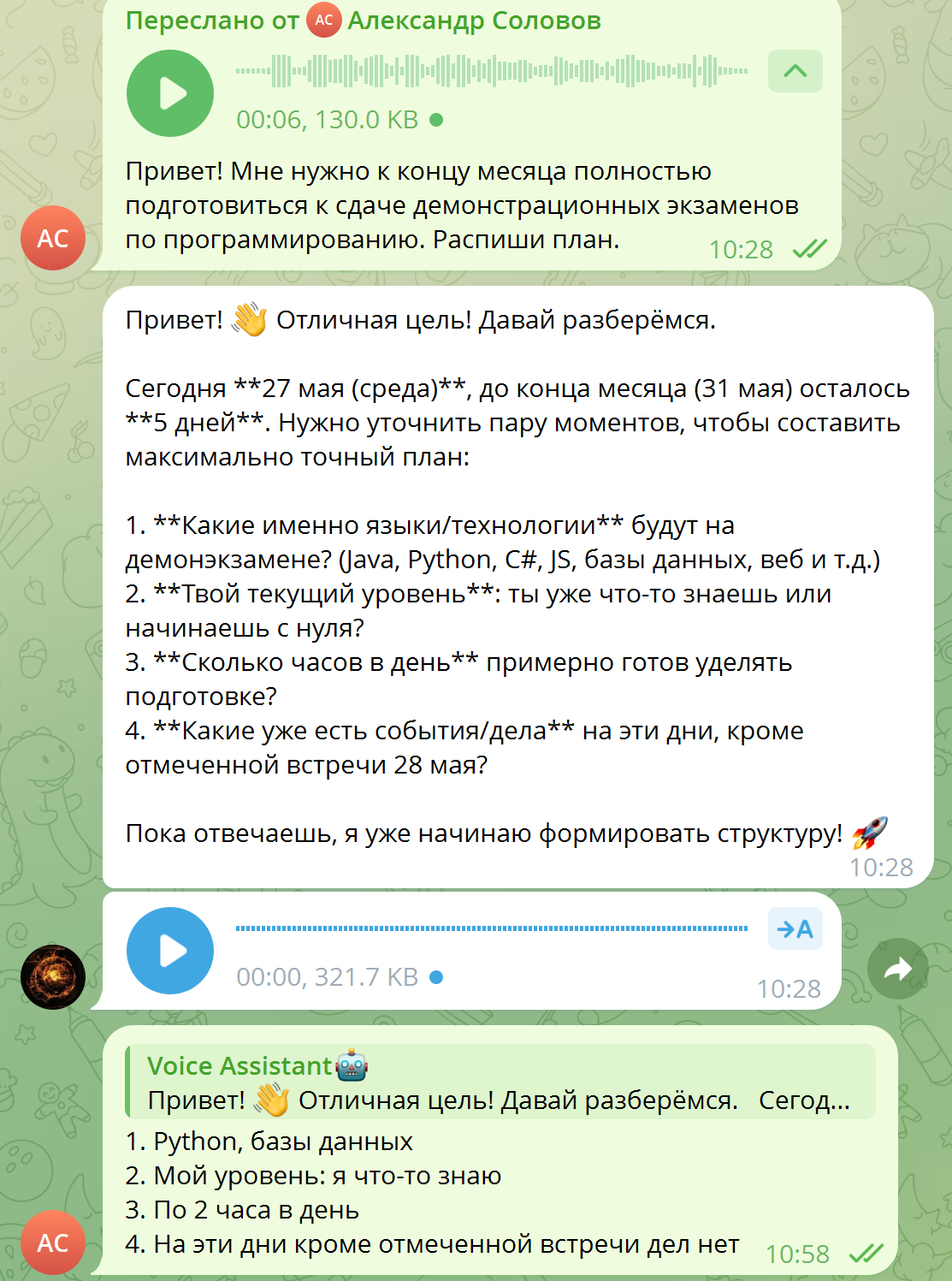
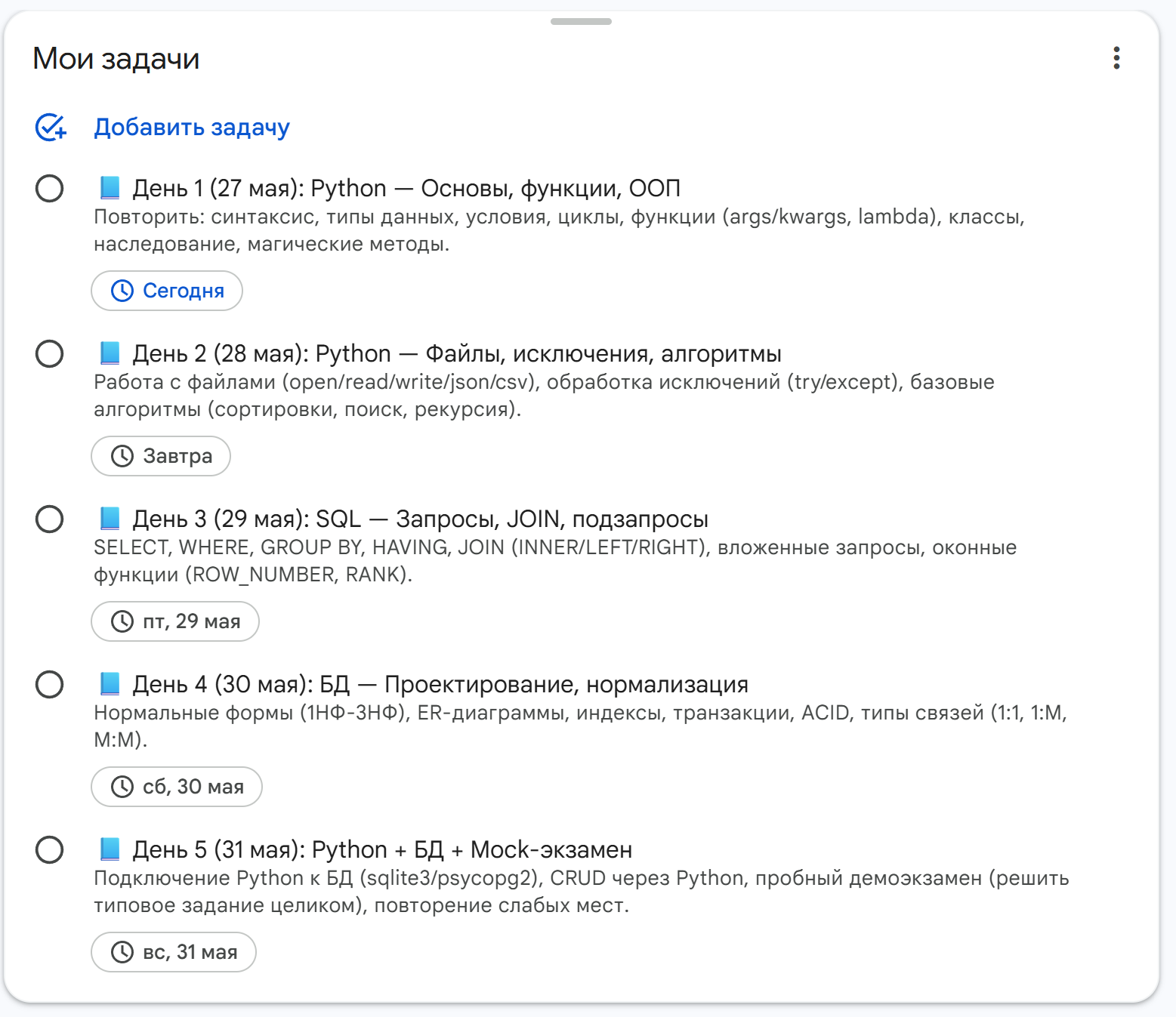
# 4. Передать в AI-цепочку (n8n → DeepSeek → ответ)
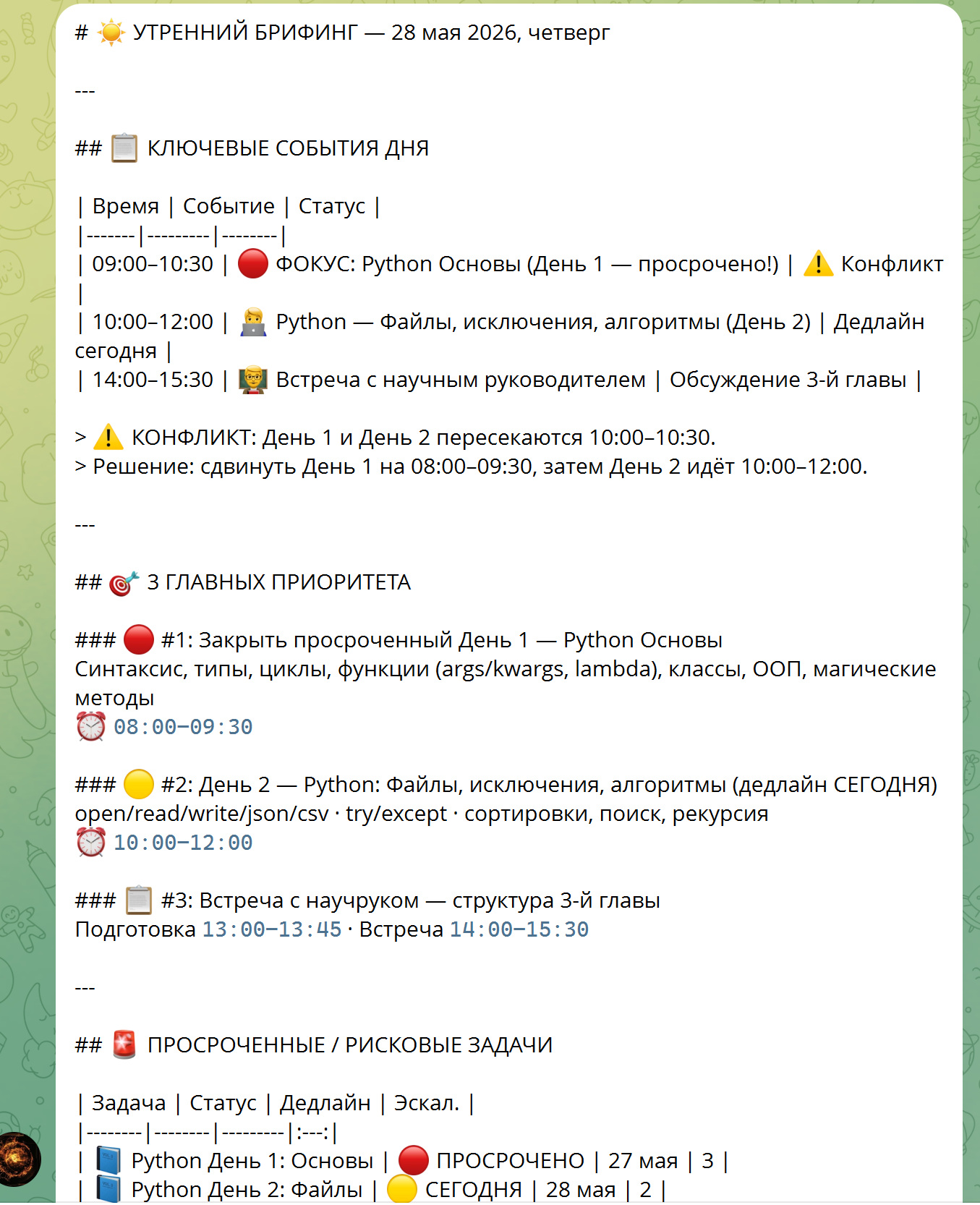
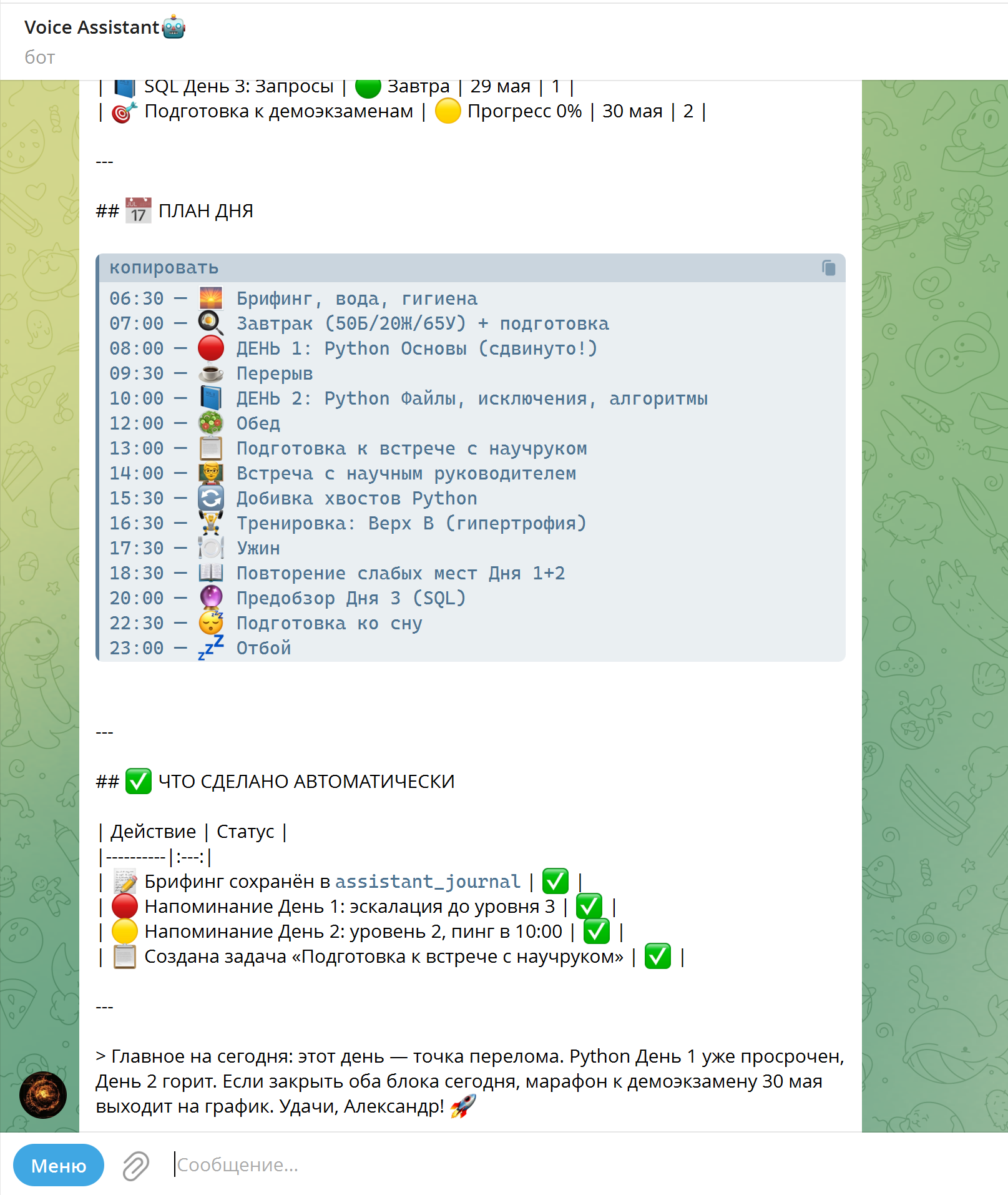
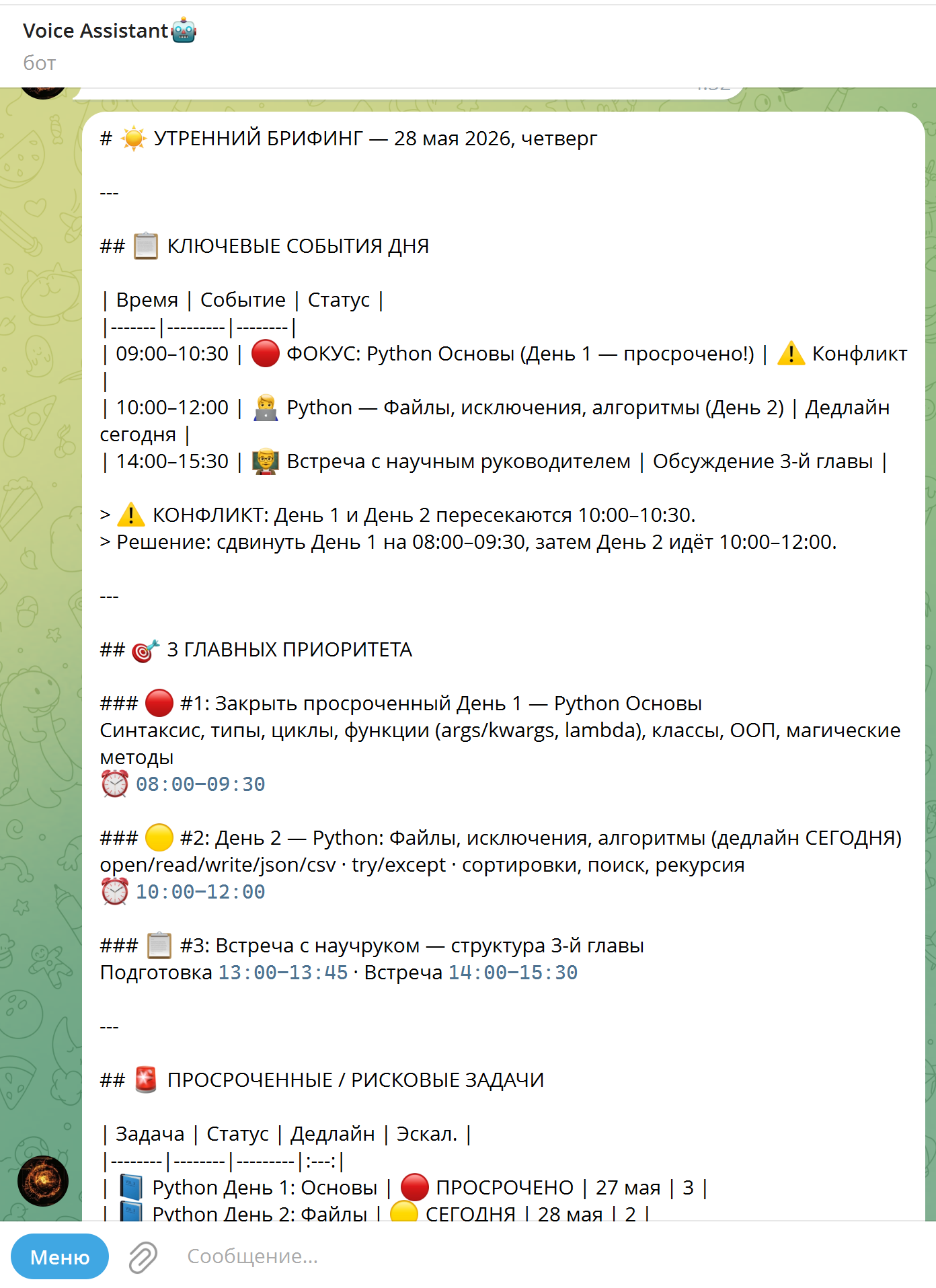
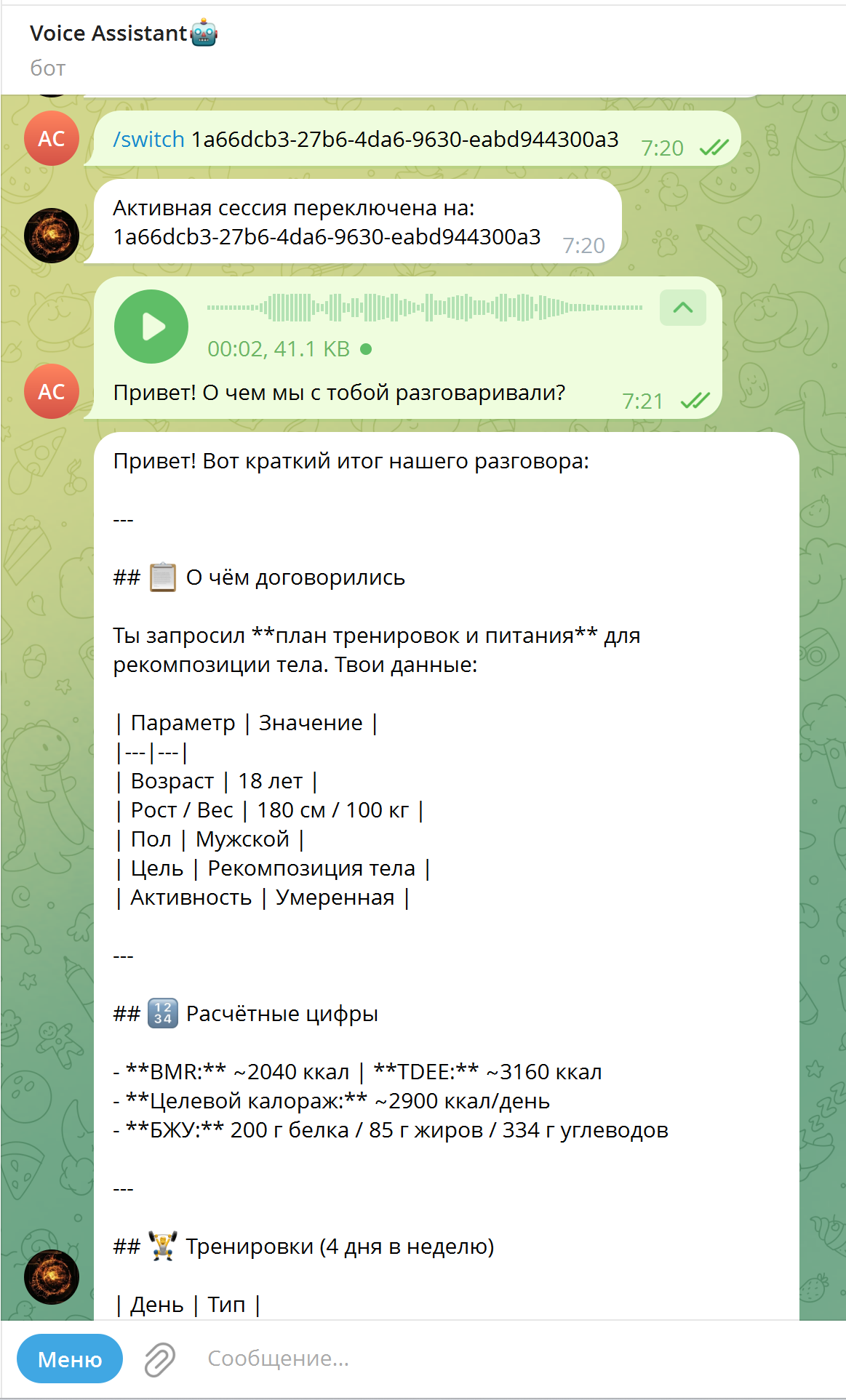
self._process_user_request(message.from_user.id, recognized_text).ogg (кодек OPUS), конвертирует через ffmpeg в монофонический output.wav 16 000 Гц, отправляет в Groq Cloud и проверяет разборчивость речи перед передачей в AI-цепочку. Полное время обработки STT: 0.20–0.50 с.
NO_SPEECH_PROB_THRESHOLD = 0.6 # вероятность тишины > 60%
LOW_CONFIDENCE_AVG_LOGPROB = -1.0 # низкая уверенность модели
NO_SPEECH_SEGMENT_RATIO_THRESHOLD = 0.5 # доля «тихих» сегментов
def is_unintelligible_transcription(transcription: Any) -> bool:
segments = transcription.segments or []
no_speech_probs = [s.no_speech_prob for s in segments]
avg_logprobs = [s.avg_logprob for s in segments]
mean_nsp = _mean(no_speech_probs)
mean_logp = _mean(avg_logprobs)
bad_ratio = _ratio_at_least(no_speech_probs, NO_SPEECH_PROB_THRESHOLD)
return (
mean_nsp >= NO_SPEECH_PROB_THRESHOLD # порог 1
or bad_ratio >= NO_SPEECH_SEGMENT_RATIO_THRESHOLD # порог 2
or mean_logp <= LOW_CONFIDENCE_AVG_LOGPROB # порог 3
or not transcription.text.strip() # порог 4
)verbose_json Groq Whisper — без дополнительных API-вызовов.


.jpeg)